
오픈AI와 구글의 AI 챗봇에 적용된 기술은 초거대 언어 모델(LLM)로 따로 분류되기도 하는데요. LLM은 그 이름처럼 사람의 언어를 읽고 쓰는 작업에 특화한 AI 모델입니다. LLM은 인터넷에 존재하는 텍스트와 문서 자료를 활용해 자연어 처리와 이해 성능을 크게 높여서,, 많은 사람들이 집과 직장에서 일상적으로 수행하는 ‘글쓰기’에 뛰어난 재주를 보여 줍니다. 챗GPT에 적용된 ‘GPT-4’나 바드에 적용된 ‘팜2(PaLM 2)’는 모두 수십개 이상의 언어를 표현한 텍스트를 입력받고 처리할 수 있습니다. 주제를 주면 시를 짓고 이메일을 쓸 수 있고 아이를 위한 동화를 지어내기도 하지요. 인터넷에서 찾은 외국어로 된 정보를 제시하고 번역하거나 전문 용어가 열거된 설명 자료를 이해하기 쉬운 평이한 표현으로 바꿔 써 주기도 합니다. 누구나 글쓰기를 하고 있기 때문에, 이러한 글쓰기 능력을 갖춘 AI 챗봇의 등장이 대중들에게 큰 반향을 일으킬 수밖에 없었습니다. 2016년 구글 알파고가 이세돌 9단과 치른 대국에서 5대 4로 승리했을 때 많은 대중에게 바둑과 같은 고도의 지적 훈련이 필요한 분야에도 AI가 인간의 능력을 넘어설 수 있음을 보여 줬지만, 그게 바둑계를 넘어 일반인의 삶을 크게 바꿔 놓은 것은 아니었죠. 이와 달리, 초거대 AI 모델을 기반으로 한 AI 챗봇은 즉각 언어와 글쓰기를 일상적으로 수행하는 전 세계 사람들의 생활을 크게 바꿔 나갈 것으로 예상할 수 있습니다.
클라우드 발판 삼아 초거대 AI도 미국 업체들이 독주
초거대 AI 모델, 더 구체적으로 말하자면 LLM을 대중적인 서비스로 제공하고 그 영향력을 빠르게 키우고 있는 것은 미국의 개발 업체입니다. 단일 기업인 오픈AI나 구글이 전 세계 인류에게 영향을 줄 수 있는 기술을 독점하고 있다는 뜻입니다. 이들이 개발하는 초거대 AI 모델 기술은 외부에 직접 제공되는 것이 아니라, 거대한 공용 서버 인프라 자원에서 작동하는 ‘종량제’ 클라우드 서비스 형태로 제공됩니다. 이용자는 인터넷을 통해 서비스 계정을 만들고, 클라우드 서비스 영역에 접속합니다. 이용자가 클라우드 서비스를 통해 초거대 AI 모델에 명령을 내리면, 개발 업체는 이 이용자가 내린 명령을 수행하기 위해 컴퓨터가 계산하는 데 쓴 자원과 데이터 용량, 작동한 시간을 측정하고 그에 비례한 비용을 청구하게 됩니다. 생산성과 성능 측면에서 실용성이 입증된 초거대 AI 모델을 일반 기업에 고스란히 제공하거나 클라우드 서비스에서 무상으로 제공하는 사례는 아직 없습니다. 따라서 초거대 AI 모델을 이용할 때 그 기술을 갖고 있는 개발 업체가 어떤 과금 정책을 갖고 있는지, 과금의 형태와 측정 대상이 되는 기준은 무엇인지가 상당히 중요한 상황이라는 것입니다.
클라우드 서비스를 통해 LLM 기능을 제공하는 서비스는 무엇을 과금 기준으로 삼을까요? 일반적으로 LLM이 언어 정보를 처리할 때 사용하는 ‘토큰(token)’이라는 단위가 선택됩니다. 토큰은 LLM에 입력된 어구, 문장이나 문단 등 큰 단위의 텍스트 데이터를 효율적으로 처리할 수 있도록 쪼개고 나눠 놓은 정보 단위이고, 기존 문자 데이터를 컴퓨터가 다루기 쉬운 형태(숫자 데이터)로 변환한 값이예요. 같은 문자 데이터는 같은 토큰으로 처리되고, 다른 문자 데이터는 서로 다른 토큰으로 처리됩니다. 현재 클라우드 서비스로 제공되는 초거대 AI 모델이나 AI 챗봇은 대부분 사용자가 요청한 작업을 수행하기 위해 토큰을 몇 개 처리했는지 측정하고, 그 토큰 처리량이나 작업 단위에 따라 가격을 매겨 놓았다고 볼 수 있습니다. 똑같은 작업을 수행해야 한다면 토큰을 적게 쓰는 것이 경제적이고 비용 면에서 사용자에게 유리하다고 할 수 있겠죠.
LLM에 입력하는 텍스트 데이터의 어구나 문장을 단어나 형태소로 분절하면 여러 개의 토큰으로 표현됩니다. 입력된 텍스트 정보를 단어나 형태소로 분절하고 숫자로 바꾸는 작업인데요. 이걸 ‘토큰화(tokenization)’라고 합니다. LLM에서 이 토큰화 작업을 ‘토크나이저(tokenizer)’라는 구성요소가 담당합니다. 텍스트 데이터를 토큰화할 때, 각 토큰에 배정되는 문자 길이가 똑같지 않고, 단어 하나에 토큰 하나, 이런 식으로 일대일 대응하지도 않습니다. 그리고 입력된 텍스트 데이터가 똑같아도 토크나이저가 어떤 방식으로 그걸 처리하느냐에 따라 LLM이 다루게 될 토큰 수가 달라집니다. 챗GPT 출시 2년 전 등장한 오픈AI의 LLM으로 GPT-3가 있는데요. 오픈AI의 설명에 따르면, 이 GPT-3를 사용할 때 토크나이저가 일반적인 영어 텍스트 데이터를 토큰화하면 네 글자 이내로 쪼갠 것을 토큰 한 개로 만들어낸다고 합니다. 어림셈하면 영어 단어 75개를 토큰 100개 정도로 처리하게 된다고 하고요.
같은 내용이라도 언어에 따라 달라지는 토큰화

준 연구원은 2023년 5월 트위터에 자신의 연구 내용을 소개하면서 이렇게 묻습니다. “LLM은 데이터를 처리하기 위해 텍스트를 토큰으로 분절해야 합니다. (챗GPT에서 사용하는 것과 동일한 토크나이저를 사용하면) 일부 언어는 다른 언어보다 10배 많은 토큰이 필요하다는 사실을 아셨습니까?” 이 블로그의 연구는 오픈AI가 바이트쌍인코딩(BPE) 알고리즘을 적용해 개발한 토크나이저 ‘cl100k_base’를 통해 여러 언어 표현의 토큰 수를 측정한 결과를 대조하고 있습니다. 준 연구원에 따르면 이 토크나이저는 오픈AI 챗GPT 무료 서비스에 사용된 ‘GPT-3.5 터보’ 모델과 유료 서비스에 사용된 ‘GPT-4’ 모델이 사용하고 있고요. cl100k_base 토크나이저의 동작을 이해하고 언어별 토큰 처리량 차이를 파악함으로써 한국을 비롯해 각 비영어권 사용자가 챗GPT나 오픈AI의 다른 초거대 AI 모델 도입시 고려해야 할 경제성을 예측할 수 있겠죠.
예니 준의 블로그 내용을 좀 소개해 보죠. 여기에 먼저 예시로 든 표현은 영어, 스페인어, 한국어, 버마어(미얀마 공용어), 암하라어(에티오피아 공용어), 이 5개국어로 의미가 같은 문장 하나를 표현한 것인데요. 한국어로 “다음 주 날씨 어때”라는 문장을 영어로 썼을 때는 토큰 7개, 스페인어로 썼을 때는 8개, 한국어로 썼을 때는 12개입니다. 미얀마어로는 토큰 61개, 암하라어로는 69개로 변환되고요. 영어와 암하라어의 토큰 수가 정말 10배쯤 차이 나네요. 다시 말씀드리지만 ‘의미가 동일한 문장 하나’의 언어에 따른 차이입니다. 준 연구원은 이 다섯 가지 언어를 포함해 52가지 언어로 된 문장을 처리한 토큰 수의 중앙값(median)을 파악했다고 합니다. 중앙값은 전체 사례를 값 크기대로 열거한 목록의 중앙 순서에 나타나는 통계치입니다.
“한국어도 비주류 언어” 네이버가 언어별 초거대 AI 필요성 말하는 이유
52가지 언어로 같은 문장 표현을 처리한 토큰 수 중앙값을 비교한 결과, 이번에도 영어가 7개로 가장 짧았어요. 버마어가 72개로 가장 길었고요. 한국어 토큰은 16개로 러시아어와 같았고, 이보다 토큰 수가 적은 언어로 스페인어, 독일어, 프랑스어, 중국어, 터키어, 스와힐리어가 있었습니다. 준 연구원은 영어를 기준 삼고 나머지 언어별 토큰 수 중앙값을 ‘배수’로 환산해 제시했습니다. 사용 인구 수가 8억명에 이르는 힌디어와 벵골어 토큰 중앙값은 영어의 5배에 달했고, 아르메니아어는 9배, 버마어는 10배 이상으로 나타났습니다. 준 연구원은 “전반적으로 (동일한 메시지를 다른 언어로 토큰화하기 위해 더 많은 토큰이 필요하다는 것은 프롬프트(명령 입력 공간)에 입력할 수 있는 정보량이 제한되고, 돈이 더 들고, 실행하는 데 더 오래 걸린다는 것을 의미한다”고 설명했습니다. 그리고 다음과 같이 비판하고 있습니다.
“자연어 처리(NLP)의 디지털 격차는 활발한 연구 분야입니다. 컴퓨터언어학회에서 발표되는 연구 논문의 70%는 오로지 영어(관련 성능, 품질)만 평가했습니다. 다국어 모델은 영어처럼 자원이 풍부한 언어보다 자원이 부족한 언어 처리시 여러 NLP 작업에 성능이 떨어집니다. W3CTechs에 따르면 영어는 인터넷 콘텐츠의 절반 이상(55.6%)을 장악했습니다. 마찬가지로, 영어는 (10년 이상 인터넷에서 수십억개 웹페이지를 수집한) 커먼 크롤 코퍼스의 46% 이상을 차지하며, 이는 구글의 T5 및 오픈AI의 GPT-3(그리고 아마도 챗GPT와 GPT-4)같은 여러 LLM 훈련에 사용되었습니다. GPT-3 훈련 데이터의 60% 이상을 커먼 크롤이 차지합니다. NLP의 디지털 격차를 해결하는 것은 AI가 중심인 기술에서 공평한 언어 표현과 성능을 보장하는 데 중요합니다. 이러한 격차를 해결하려면 NLP 영역에서 더 포용적이고 다양한 언어 환경을 조성해 자원이 부족한 언어 (처리 기술) 개발에 우선순위를 두고 투자하는 연구자, 개발자, 언어학자의 공동 노력이 필요합니다.”
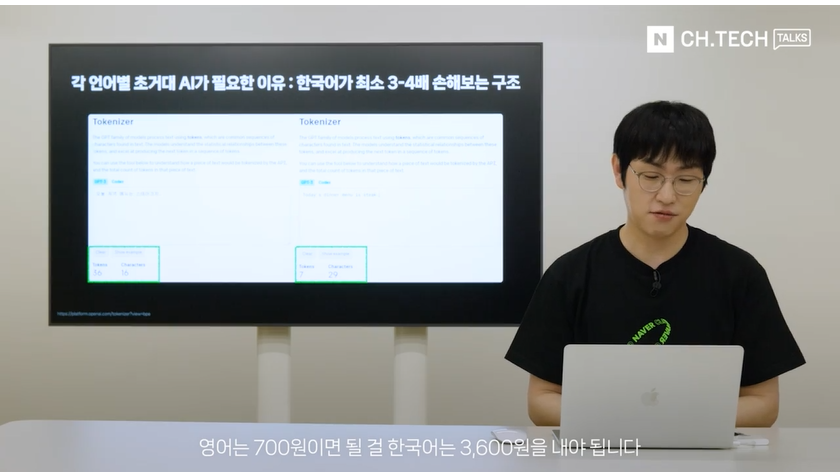
“(전략) 글로벌 기업은 이 토큰을 일단 사전을 만들어 놓고 그 토큰 사전에 있는 걸 다 꺼내서 쓰면 25개국 이상의 (언어로 된) 글이 다 써질 수 있게 만들어요. 그러다보니 토큰 사전을 만들 때 영어에 최적화하게 됩니다. 영어는 단어 하나당 토큰 하나 이렇게 배치할 수 있고, 아주 자주 쓰이는 표현, 예를 들면 ‘That’s Okay’ 이런 거는 그냥 여러 단어를 하나의 토큰에 배정해 주기도 합니다. 그런데 비주류 언어인 한국어는 그렇게 배정 안 해주고요. 정말 잘 해줘야 글자 하나 배정해주거나 혹은 거의 초성, 중성, 종성 같은 개념으로 쪼개서 배정을 해줍니다. 그렇게 해야 글을 다 쓸 수 있으니까요. 그래서 무슨 사태가 발생하느냐, 여기 나와 있는 이겁니다. ‘오늘 저녁 메뉴는 스테이크지!’라고 하는 16자 밖에 안 되는(문장)인데 토큰을 36개나 써야 됩니다. 같은 의미의 영어 표현은 29자나 쓰지만 토큰은 7개만 써도 돼요. 우리가 주목할 점은 초거대 AI는 과금을 할 때 토큰당 과금을 합니다. 편의상 토큰 하나당 100원이라고 칠게요. 영어는 700원이면 될 걸 한국어는 3600원을 내야 됩니다. 그리고 토큰 하나씩 쓰면서 이렇게 글을 만들어갑니다. 7번만 쓰면 될 걸 36번을 써야 됩니다. 속도가 5분의1로 줄어든다는 뜻입니다. 초거대 AI는 이전에 나눈 모든 대화나 모든 글을 다 읽고 글을 쓰는데 이 읽을 수 있는 양도 토큰 단위입니다. 읽을 수 있는 글의 길이도 5분의 1로 줄어든다는 뜻입니다. 한 줄 요약하면 품질도 안 좋은데 속도도 느리면서 가격만 비싼 모델을 써야 한다는 뜻입니다. 한국어는 비주류 언어이기 때문이죠. 혹자는 GPT-3가 토큰 사전 크기를 5만개에서 10만 개로 늘리면서 문제가 해소됐다고 하는데 아닙니다. 똑같은 표현(오늘 저녁 메뉴는 스테이크지!) 토큰 수가 21개로 좀 줄긴 했지만 이것도 많죠. 저희 하이퍼클로바는 똑 같은 표현에 대해 7토큰이면 됩니다. 모델 역량이 비슷하다는 전제에서 3배 빠르고, 3배 저렴하고, 3배 더 좋은 품질의 글을 쓸 수 있다는 겁니다. 각 언어 중심으로 영어와 다른 언어를 섞는 초거대 AI를 만들어야 되는 현실적인 이유가 바로 이겁니다.”
AI 사용자가 처하는 경제적 불평등은 AI 투명성과 윤리 문제
하 센터장의 주장은 오픈AI GPT-3, GPT-4에 맞서 하이퍼클로바, 하이퍼클로바X를 개발하는 네이버의 입장을 대변하는 것일 수 있습니다. 네이버가 독자적인 LLM과 초거대 AI 모델을 개발하는 당위성을 얘기하는 것은 회사의 이익과 연결돼 있기 때문에 중립적으로 해석하는 데 제약이 따르죠. 그리고 LLM으로 같은 정보를 다루면서 토큰을 더 많이 쓰는 언어일수록 더 많은 비용이 부과되는 상황이 당장은 심각해 보이지 않을 수 있습니다.
하지만 언어에 따른 토큰화 방식 차이로 비용 편차가 큰 LLM과 이를 활용하는 AI 서비스가 대중화할 때 각 언어 화자가 처하는 AI 사용 환경에선 실제로 큰 문제가 될 수 있습니다. 비용에 따른 격차가 주 사용 언어와 같은 요소로 결정되는 것은 공평하지 않다는 인식을 받아들인다면 지금도 충분히 문제시할 수 있고요. 사용 언어에 따라 디지털 격차와 불평등은 앞으로 점점 더 크게 나타날 수 있기 때문이죠. 이런 경제적 불평등을 이해하고 해소하는 것 자체를 넓은 범주의 AI 윤리 문제로 연결할 수도 있습니다.
챗GPT처럼 상업적인 서비스가 본격적으로 제공되면서 학계에 이런 문제를 직접 제기하는 움직임도 형성되고 있습니다. 정식 학술지 발표보다 빠르게 최신 연구 결과를 소개하는 코넬대 웹사이트 ‘아카이브(arxiv)’에 2023년 5월 23일 제출된 논문 ‘Do All Languages Cost the Same? Tokenization in the Era of Commercial Language Models(모든 언어 비용은 동일한가? 상업용 언어 모델 시대의 토큰화)’의 연구자들이 던진 메시지가 그런 사례죠. 이들은 직접적으로 LLM 기술에 대한 가격이 주 사용 언어로 차별당해서는 안 된다고 비판합니다. 해당 논문의 초록을 일부 옮겨 보면 다음과 같습니다.
“(전략) API 공급업체는 사용량, 특히 기반 언어 모델에서 처리하거나 생성한 토큰의 수에 따라 사용자에게 비용을 청구합니다. 그러나 같은 정보를 다른 언어로 전달하는 데 필요한 토큰 수에 큰 차이가 있는 학습 데이터와 모델에 따라 토큰의 구성은 다릅니다. 이 연구는 이러한 비균일성이 언어 간 API 가격 정책의 공정성에 미치는 영향을 분석합니다. 유형이 다양한 22개 언어 벤치마크에서 오픈AI의 언어모델 API 비용과 유용성에 대해 체계적인 분석을 수행합니다. 우리는 지원된 여러 언어 화자가 (상대적으로) 나쁜 결과를 얻는 동안 과도하게 과금된다는 증거를 제시합니다. 이 화자는 처음부터 API를 저렴하게 쓸 수 없는 지역에 있는 경향이 있습니다. 우리는 이러한 분석을 통해 공급업체가 언어 모델 API 가격 정책 투명성을 높이고 더 공평하게 만들 것을 권고합니다.”
—
솔트룩스 네이버블로그 ‘인공지능 인사이트’ 필진으로서 작성한 열일곱 번째 정기 원고. 230803 솔트룩스 네이버블로그 포스팅으로 게재됨. 240114 개인 블로그에 원문 비공개로 올림. 240721 공개로 전환.